Week 13: Software engineering in scientific projects
Note: Week 13 covers April 13 through 19 of 2026
On the data science project
Defining dependencies aka software engineering
As I’ve mentioned before,
I’m working on the side on a computer vision project.
The previous work was more of a proof-of-concept,
rather than a complete software solution.
As such, I, who happen to know a thing or two about software engineering,
thought it best to start by adding the explicit list of dependencies needed to run the project.
Since I’m bored of always using the pip package manager, with the usual requirements.txt file,
I opted instead for the hot stuff: the uv package manager.
Finding out
I grepped the import statements of the project
to figure them out.
That’s a good initial heuristic for the package name,
but it’s not always conclusive.
For instance, on seeing the statement
import cv2
one might be tempted to
uv add cv2.
However, the name of the
OpenCV
Python library is, quite aptly,
opencv-python.
Here’s the complete list of dependencies from the pyproject.toml:
1dependencies = [
2 "fiona>=1.10.1",
3 "geopandas>=1.1.3",
4 "jupyter>=1.1.1",
5 "matplotlib>=3.10.8",
6 "numpy>=2.4.4",
7 "opencv-python>=4.13.0.92",
8 "shapely>=2.1.2",
9]
Just to give you an idea of what kind of project this is 👀
The plan
I met with the project lead to tell him about the course of action I came up with:
-
First, let’s organise the codebase somewhat to allow for an easier refactoring. As of now, the Python modules for saving and doing image segmentation are so tightly coupled that it would be awkward to mould them into a new program.
-
Consider using an alternative to Jupyter notebooks such as marimo. Here’s what the authors of marimo have to say about its advantages over Jupyter notebooks:
marimo is an open-source programming environment that blends the best parts of interactive computing with the rigor of traditional software development. Unlike Jupyter notebooks, marimo notebooks are reproducible, execute reactively, have interactive elements built-in (no callbacks!), stored as pure Python, versionable with Git, deployable as web apps, and executable as scripts.
We also noticed some potential issues we might run into considering the way they photographed the materials we’re working with. There’s only hoping we can manage to do our best to get around them. Fingers crossed.
My CvLAC profile
The Ministry of Science has this network for Latin American researchers called CvLAC, which stands for Curriculum Vitae for Latin America and the Caribbean. About a month ago or so, my boss asked me to sign up there as his superiors sometimes prompt him for that info. Finally, after such a long wait, I got the account activation code.
So, here’s my very empty CV: https://scienti.minciencias.gov.co/cvlac/visualizador/generarCurriculoCv.do?cod_rh=0002455640
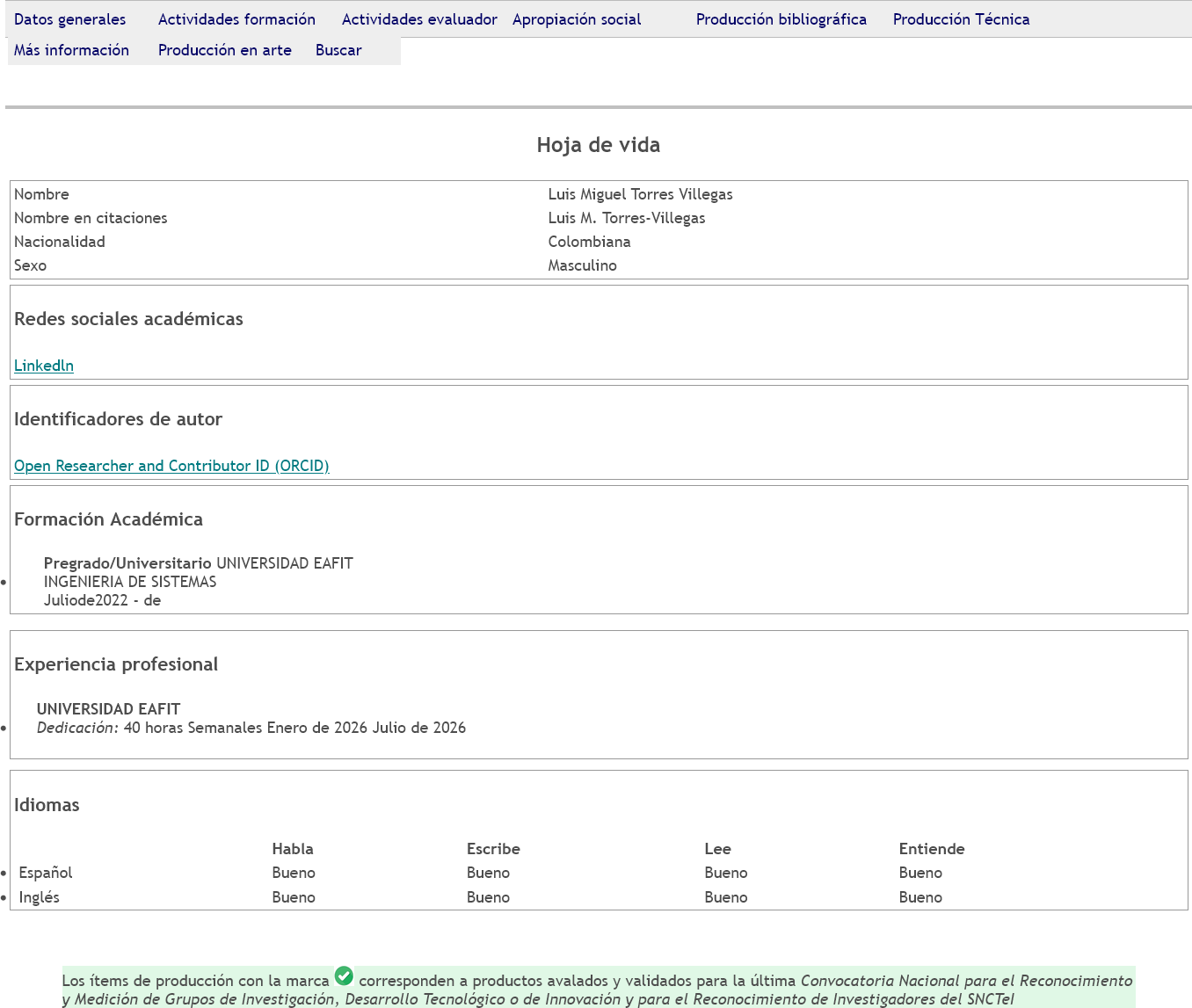
My CvLAC curriculum.
QGIS and GeoPandas course
JAGE and EMB have to teach some courses to fulfil the requirements of their scholarships. To that end, they decided to teach the fundamentals of QGIS and GeoPandas.
We learnt how to load layers of shapefiles, convert their CRS to a standard one, change the styling, draw on the map, and do more or less the same but with Python using GeoPandas.
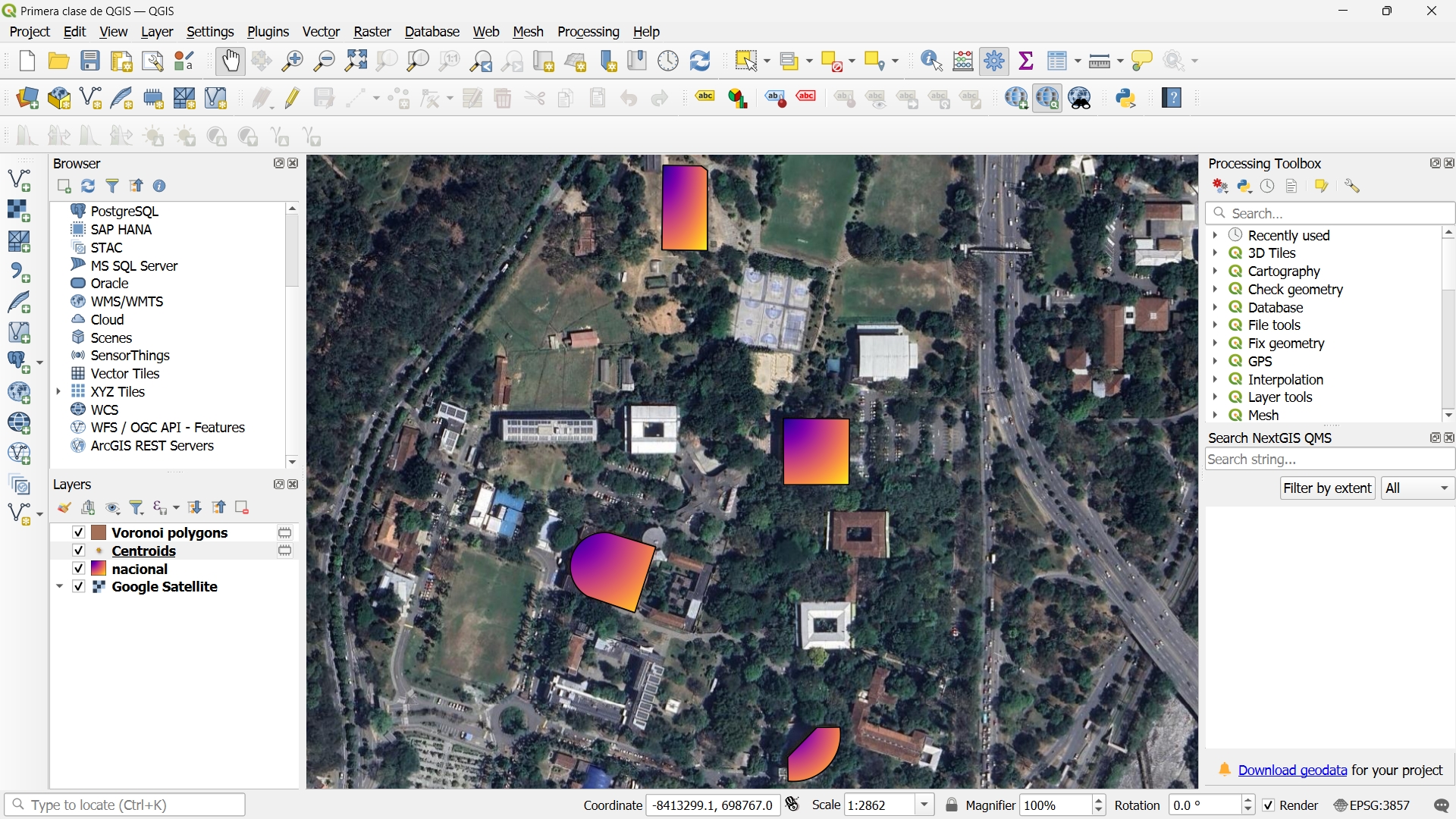
Mapping some of the buildings of the Central Campus of the Universidad Nacional de Colombia.
Playing Tetris within QGIS.
Setting up the GitHub repositories for the research group
I met with the team on early Wednesday morning to discuss how to set up the new GitHub organisation. More importantly, we looked into the details of doing the migration of the rise-group GitHub repos over to the new organisation. Most of them have historically stored data, some of which consists of large binary files, in the version control system. One of my tasks is to refactor the repos so that the code is (mostly) independent from the data.
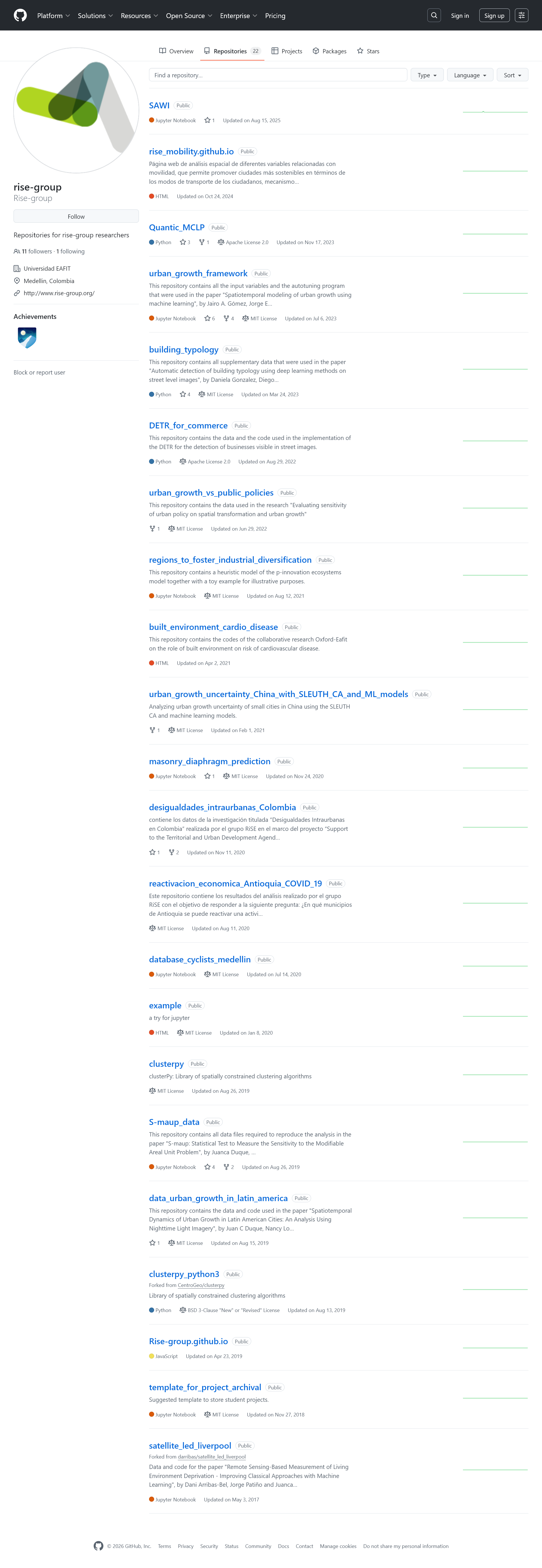
List of repos under the Rise-group account.
Consulting with professor Daniel Correa Botero
On Thursday, I met with professor Daniel Correa Botero to ask for his advice on how to get started with the special project I have to submit in fullfilment of my internship. His overall impression was that the project is quite hairy, and that I should get started achieving simpler tasks incrementally. He desribed some steps he would take to achieve the main goal which I found to be helpful guidance, as far as it goes.
Reading papers on good practices for scientific computing
My boss told me to read these two papers on good practices for scientific computing, for us to discuss on a later date:
-
Wilson, Greg, D. A. Aruliah, C. Titus Brown, et al. 2014. ‘Best Practices for Scientific Computing’. PLOS Biology 12 (1): e1001745. https://doi.org/10.1371/journal.pbio.1001745.
-
Wilson, Greg, Jennifer Bryan, Karen Cranston, Justin Kitzes, Lex Nederbragt, and Tracy K. Teal. 2017. ‘Good Enough Practices in Scientific Computing’. PLOS Computational Biology 13 (6): e1005510. https://doi.org/10.1371/journal.pcbi.1005510.
Some quotes from the papers:
-
On change:
Change is hard, and if researchers don’t see those benefits quickly enough to justify the pain, they will almost certainly switch back to their old way of doing things.
-
On the target audience of scientific computing:
Unlike traditional commercial software developers, but very much like developers in open source projects or startups, scientific programmers usually don’t get their requirements from customers, and their requirements are rarely frozen. In fact, scientists often can’t know what their programs should do next until the current version has produced some results. This challenges design approaches that rely on specifying requirements in advance.
-
On getting to a prototype quickly:
Even when it is known before coding begins that a low-level language will ultimately be necessary, rapid prototyping in a high-level language helps programmers make and evaluate design decisions quickly.
-
On implementing these suggestions:
Nevertheless, we do not recommend that research groups attempt to implement all of these recommendations at once, but instead suggest that these tools be introduced incrementally over a period of time.